📌 셸 정렬
- 셸 정렬(Shell Sort): 삽입 정렬의 장점은 살리고 단점은 보완하여 더 빠르게 정렬하는 알고리즘.
삽입 정렬은 다음과 같은 특징을 갖고 있다.
1. 이미 정렬을 마쳤거나 정렬이 거의 끝나가는 상태에서는 속도가 빠르다. (장점)
2. 삽입할 위치가 멀리 떨어져 있으면 이동 횟수가 많아진다. (단점)
앞에서 말했듯 셸 정렬은 삽입 정렬의 장점은 살리고 단점은 보완한 알고리즘이다.
셸 정렬은 먼저 정렬할 배열의 원소를 그룹으로 나누어 각 그룹별로 정렬을 수행한 뒤, 정렬된 그룹을 합치는 작업을 반복해 원소의 이동 횟수를 줄이는 방법이다.

우선, 삽입 정렬의 경우 '주목한 원소보다 앞 쪽에서 이전의 값들과 비교하며 삽입을 수행'하는 정렬 알고리즘이다. 삽입 정렬의 가장 큰 장점은 '거의 정렬이 되어 있는 상태일 경우 속도가 빠르다' 것이다. 예를 들어 [1, 2, 4, 3, 5, 6, 7, 8]의 배열에 삽입 정렬을 수행할 경우 매우 빠른 속도로 정렬이 완료될 것이다. 하지만 이와 반대로 '삽입할 위치가 멀리 떨어져 있을 경우 이동 횟수가 많아져 속도가 느리다'는 단점을 지니고 있다. 예를 들어 [2, 3, 4, 5, 6, 7, 8, 1]의 배열이 있을 경우 1을 정렬하기 위해선 8, 7, 6, 5, 4, 3, 2를 모두 비교하며 맨 앞까지 도달해야 할 것이다.
이러한 삽입 정렬의 장점을 살리면서 단점을 보완하는 알고리즘이 셸 정렬이다. 그림 1을 보면 4개의 그룹 -> 2개의 그룹 -> 1개의 그룹으로 정렬을 수행하는 것을 볼 수 있다. 이렇게 그룹으로 나누면서 정렬을 수행한 뒤 다시 합치는 작업을 반복하게 될 경우 삽입 정렬의 단점을 보완하면서 이와 함께 삽입 정렬의 장점을 살릴 수 있다.
1. 삽입 정렬의 단점: 이동횟수가 많아져 속도가 느리다.
∴ 그룹으로 나누면서 정렬을 수행하기 때문에 이동 횟수를 줄여 삽입 정렬의 단점을 해소할 수 있다.
2. 삽입 정렬의 장점: 거의 정렬되어 있는 상태일 경우 속도가 빠르다.
∴ 그룹으로 나누면서 정렬을 수행하였기 때문에 마지막 1개의 그룹에서 정렬을 수행할 경우 거의 정렬이 되어 있는 상태이기 때문에 삽입 정렬의 장점을 살릴 수 있다.
- 셸 정렬의 장·단점
셸 정렬은 삽입 정렬을 개선한 알고리즘이기 때문에 삽입 정렬보다 성능이 우수하다는 장점을 지니고 있다.
하지만 셸 정렬은 그룹(=간격)을 어떻게 나누는지에 따라 성능이 달라진다는 단점을 지니고 있다. 즉, 그룹을 잘못 설정할 경우 성능이 매우 떨어질 수 있다.
또한 셸 정렬은 이웃하지 않고 설정한 간격에 따라 떨어져 있는 원소들을 비교, 교환하기 때문에 안정적이지가 않다는 단점을 지니고 있다.
- 셸 정렬 파이썬 코드
# 셸 정렬 알고리즘 구현
def shell_sort(a: List) -> None:
"""셸 정렬(h*3 + 1 수열 사용)"""
n = len(a)
h = 1
while h < n // 9:
h = h * 3 + 1
while h > 0:
for i in range(h, n):
j = i - h
tmp = a[i]
while j >= 0 and a[j] > tmp:
a[j + h] = a[j]
j -= h
a[j + h] = tmp
h //= 3위의 코드를 보면 h 변수를 볼 수 있는데, 이는 셸 정렬의 가장 중요한 특징인 그룹(간격)이다. h를 어떻게 설정하냐에 따라 셸 정렬의 성능이 달라진다.
- 셸 정렬의 시간 복잡도
최선의 경우: O(n)
보통의 경우: O(n^1.5)
최악의 경우: O(n^2)
📌 퀵 정렬
- 퀵 정렬(Quick Sort): 일반적으로 사용되는 아주 빠른 정렬 알고리즘으로, 분할 정복(divide and conquer)을 사용한 정렬 알고리즘 중 하나이다.
퀵 정렬은 하나의 원소를 선택하여 그룹을 나누는데, 기준을 나누는 원소를 피벗(pivot)이라고 한다. 퀵 정렬은 아래의 그림과 같이 동작한다.
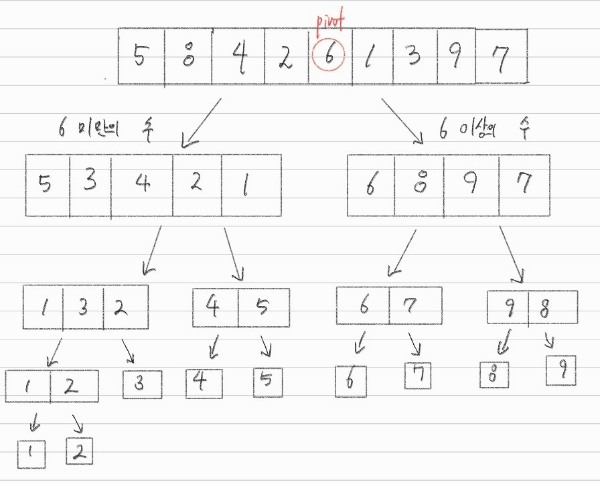
퀵 정렬의 동작 방식은 다음과 같이 이루어진다고 볼 수 있다.
1. 리스트에서 기준이 되는 하나의 원소를 선택한다. (= pivot)
2. pivot보다 작은 원소들을 왼쪽 리스트에 위치시키고, pivot보다 큰 원소들을 오른쪽 리스트에 위치시켜 pivot을 기준으로 두 개의 그룹으로 나눈다.
3. 각각의 그룹들을 재귀적으로 퀵 정렬을 이용해 정렬한다. 즉, 나눠진 각각의 그룹을 또 다시 하나의 기준이 되는 원소를 선택해 해당 원소를 기준으로 2개의 그룹으로 나눈다.
4. 더 이상 나눠지지 않으면 정렬이 완료된다.
- 퀵 정렬의 장·단점
퀵 정렬은 대부분의 경우 빠른 속도를 보인다는 장점을 갖고 있다. 평균적인 시간 복잡도는 O(nlogn)으로, 다른 정렬 알고리즘 중 빠른 편에 속한다.
또한 퀵 정렬은 원래의 배열을 정렬하는 in-place 알고리즘이므로 추가적인 메모리 공간을 필요로 하지 않는다. (in-place: 정렬하고자 하는 배열 안에서 교환하는 방식)
퀵 정렬은 피벗을 무엇으로 설정하냐에 따라 성능이 달라질 수도 있다는 단점을 지니고 있다. 최악의 경우에는 O(n^2)라는 시간 복잡도가 나오게 된다. 그리고 퀵 정렬은 셸 정렬과 마찬가지로 안정적이지가 않다는 단점을 지니고 있다. 이러한 단점들을 보았을 때, 셸 정렬과 퀵 정렬의 단점은 유사한 측면을 보이고 있다. 셸 정렬은 그룹(=간격)을 어떻게 설정하는지에 따라, 퀵 정렬은 pivot을 무엇으로 설정하는지에 따라 성능이 달라진다는 단점을 보이고, 셸 정렬과 퀵 정렬 모두 안정적이지가 않다는 단점을 보인다.
또한 퀵 정렬은 재귀를 사용하기 때문에 재귀를 계속해서 호출할수록 스택 메모리 사용량이 늘어난다는 단점이 있다.
- 퀵 정렬 파이썬 코드
# 퀵 정렬 알고리즘 구현
def qsort(a: List, left: int, right: int) -> None:
"""a[left] ~ a[right]를 퀵 정렬"""
pl = left # 왼쪽 커서
pr = right # 오른쪽 커서
pivot = a[(left + right) // 2] # 피벗 (가운데 원소)
while pl <= pr:
while a[pl] < pivot: pl += 1
while a[pr] > pivot: pr -= 1
if pl <= pr:
a[pl], a[pr] = a[pr], a[pl]
pl += 1
pr -= 1
if left < pr: qsort(a, left, pr)
if right > pl: qsort(a, pl, right)
def quick_sort(a: List) -> None:
"""퀵 정렬"""
qsort(a, 0, len(a)-1)위의 파이썬 코드를 보면 피벗을 가운데 원소로 설정했다는 것을 볼 수 있다. 하지만 피벗을 굳이 가운데 원소로 설정하지 않아도 되며, 피벗을 무엇으로 설정하는지에 따라 퀵 정렬의 성능이 결정된다.
그리고 재귀 호출을 하는 코드를 볼 수 있다. 이렇게 재귀 호출을 하며 계속해서 피벗을 기준으로 두 개의 리스트로 나누는데, 재귀 호출의 깊이가 깊어질수록 스택 메모리의 사용량이 늘어난다는 단점을 갖고 있다.
- 퀵 정렬의 시간 복잡도
최선의 경우: O(nlogn)
보통의 경우: O(nlogn)
최악의 경우: O(n^2)
📌 병합 정렬
- 병합 정렬(Merge Sort): 배열을 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후 병합하는 작업을 반복하는 알고리즘으로, 분할 정복(divide and conquer)을 사용한 정렬 알고리즘 중 하나이다.
병합 정렬 또한 퀵 정렬과 같이 분할 정복 알고리즘을 사용한다. 병합 정렬은 아래의 그림과 같이 수행된다.

병합 정렬은 다음과 같은 순서로 수행된다.
1. 배열을 앞부분과 뒷부분으로 나눈다.
2. 나누어진 배열을 재귀적으로 병합 정렬을 수행하며 정렬한다.
3. 나누어진 배열을 다시 병합한다. 이 때 정렬된 두 개의 부분 배열을 병합하는 과정에서 추가적인 메모리가 사용된다.
- 병합 정렬의 장·단점
병합 정렬은 퀵 정렬과 마찬가지로 대부분의 경우 빠른 성능을 보인다는 장점을 갖고 있다. 병합 정렬은 대부분의 경우 O(nlogn)의 시간 복잡도를 가지며 입력 데이터가 큰 경우에도 빠른 정렬이 가능하다.
병합 정렬은 퀵 정렬과 다르게 서로 떨어져 있는 원소를 교환하는 것이 아니므로 안정적이다.
하지만 병합 정렬은 퀵 정렬과 마찬가지로 재귀를 사용하기 때문에 재귀를 계속해서 호출할수록 스택 메모리 사용량이 늘어난다는 단점이 있다.
또한 병합 정렬은 퀵 정렬과 다르게 추가적인 메모리를 사용한다는 단점을 갖고 있다. 앞에서 병합 정렬의 순서를 간단하게 설명할 때 말했듯, 병합 정렬은 배열들을 분할한 뒤 정렬된 배열들을 병합할 때 추가적인 메모리를 사용한다. 그렇기 때문에 입력 데이터의 크기가 커지면 그만큼 메모리 사용량도 증가하게 된다.
- 병합 정렬 파이썬 코드
# 병합 정렬 알고리즘 구현
def merge_sort(a: List) -> None:
"""병합 정렬"""
def _merge_sort(a: List, left: int, right: int) -> None:
"""a[left] ~ a[right]를 재귀적으로 병합 정렬"""
if left < right:
center = (left + right) // 2
_merge_sort(a, left, center) # 배열 앞부분을 병합 정렬
_merge_sort(a, center, right) # 배열 뒷부분을 병합 정렬
p = j = 0
i = k = left
while i <= center:
buff[p] = a[i]
p += 1
i += 1
while i <= right and j < p:
if buff[j] <= a[i]:
a[k] = buff[j]
j += 1
else:
a[k] = a[i]
i += 1
k += 1
while j < p:
a[k] = buff[j]
k += 1
j += 1
n = len(a) # 배열의 원소 수
buff = [None] * n # 병합 결과를 임시 저장하는 작업용 배열을 생성
_merge_sort(a, 0, n - 1) # 배열 전체를 병합 정렬
del buff # 작업용 배열을 소멸위의 파이썬 코드를 보면, 병합 정렬은 재귀를 사용하여 배열을 두 개의 하위 배열들로 나눈다는 것을 볼 수 있다. 그리고 위의 코드를 보면 buff 변수가 보이는데, 이는 병합할 때 사용하는 추가적인 메모리임을 알 수 있다.
- 병합 정렬의 시간 복잡도
최선의 경우: O(nlogn)
보통의 경우: O(nlogn)
최악의 경우: O(nlogn)
- 퀵 정렬과 병합 정렬 비교
앞에서의 설명들을 통해 퀵 정렬과 병합 정렬은 다른 정렬 알고리즘들 중 빠른 속도를 보이는 알고리즘 중의 하나이며, 분할 정복 알고리즘을 기반으로 하고 있다는 것을 알 수 있다.
둘 다 분할 정복 알고리즘을 기반으로 하고 있지만, 두 정렬 간에도 차이점은 존재한다.
우선, 하위 리스트를 나눌 때에 차이를 볼 수 있다. 퀵 정렬은 pivot을 기준으로 하위 리스트들을 나누며, 그렇기 때문에 여러 비율로 하위 리스트들이 나뉜다. 하지만 병합 정렬은 하위 리스트들이 항상 절반으로 나뉜다.
두 번째로, 최악의 경우 시간복잡도가 다를 수 있다. 두 정렬 모두 평균적으로는 O(nlogn)을 갖지만, 최악의 경우에서는 퀵 정렬은 O(n^2)의 시간 복잡도를 갖고 병합 정렬은 O(nlogn)의 시간 복잡도를 갖는다.
세 번째로 안정성(Stable)에서 차이를 보인다. 앞서 말했듯 퀵 정렬은 pivot을 기준으로 pivot 미만의 값들이 모인 리스트와 pivot 이상의 값들이 모인 리스트로 나뉘기 때문에 웬만해서는 안정적이지가 않다. 물론 구현 방식이나 배열에 따라 안정적일 수도 있다. 하지만 병합 정렬은 기존의 배열들을 건드리지 않고 반으로 나누기 때문에 안정적이다.
네 번째로 정렬 방식이 다르다. 퀵 정렬은 기존의 배열을 변경하며 내부 정렬을 수행하지만, 병합 정렬은 추가적인 메모리를 사용하여 외부 정렬을 수행한다.
이외에도 퀵 정렬과 병합 정렬에는 여러 차이점이 존재한다.
📌 힙 정렬
- 힙 정렬(heap sort): 선택 정렬을 응용한 알고리즘으로, 힙 자료구조를 사용하여 정렬하는 알고리즘이다.
바로 위에서 말했듯, 힙 정렬은 힙 자료구조를 사용하여 정렬하는 알고리즘이다. 힙은 '부모의 값이 자식의 값보다 항상 크다'(= max heap)는 조건을 만족하거나 '부모의 값이 자식의 값보다 항상 작다'(= min heap)는 조건을 만족하는 완전 이진 트리로, 최솟값 혹은 최대값을 빠르게 찾아낼 수 있다.
완전 이진 트리에서 '완전'과 '이진'의 뜻은 다음과 같다.
'완전': 부모는 왼쪽 자식부터 추가한다.
'이진': 부모가 가질 수 있는 자식의 최대 수는 2개이다.
힙 정렬은 '힙에 최대값 혹은 최솟값이 루트에 위치한다'는 특징을 이용하여 정렬하는 알고리즘으로, 다음과 같은 과정으로 수행된다.
1. 주어진 배열을 최대 힙(max heap) 또는 최소 힙(min heap)으로 변환한다.
2. 힙에서 최대값 혹은 최솟값을 꺼내 배열을 맨 끝으로 이동한다.
3. 힙의 크기를 1 감소시킨 뒤 1번 순서부터 다시 시작한다.
4. 힙의 크기가 1이 될 때까지 2번 순서와 3번 순서를 반복한다.
- 힙 정렬 파이썬 코드
# 힙 정렬 알고리즘
def heap_sort(a: List) -> None:
"""힙 정렬"""
def down_heap(a: List, left: int, right: int) -> None:
temp = a[left] # root
parent = left
while parent < (right + 1) // 2:
cl = parent * 2 + 1 # left child
cr = cl + 1 # right child
child = cr if cr <= right and a[cr] > a[cl] else cl # 큰 값을 선택
if temp >= a[child]:
break
a[parent] = a[child]
parent = child
a[parent] = temp
n = len(a) # 배열 a의 길이
for i in range((n-1) // 2, -1, -1):
down_heap(a, i, n-1)
for i in range(n-1, 0, -1):
a[0], a[i] = a[i], a[0]
down_heap(a, 0, i-1)- 힙 정렬의 시간 복잡도
최선의 경우: O(nlogn)
보통의 경우: O(nlogn)
최악의 경우: O(nlogn)
📌 시간 복잡도 정리
블로그에서 설명했던 정렬들의 시간 복잡도를 전체적으로 나타내자면 다음과 같다.
| 정렬 | Best | Avg | Worst |
| 버블 정렬 | n² | n² | n² |
| 선택 정렬 | n² | n² | n² |
| 삽입 정렬 | n | n² | n² |
| 셸 정렬 | n | n^1.5 | n² |
| 퀵 정렬 | nlog₂n | nlog₂n | n² |
| 병합 정렬 | nlog₂n | nlog₂n | nlog₂n |
| 힙 정렬 | nlog₂n | nlog₂n | nlog₂n |
여태 설명한 정렬들 중 어느 것이 빠른가? 라고 물어본다면, 이는 'OO 정렬이 가장 빠르며, 그 다음으로는 OO 정렬이 빠르다' 라고 단언하면서 말할 수 없다. 왜냐하면 정렬 알고리즘의 속도는 데이터의 구성 및 크기, 알고리즘 구현 방식 등 여러 가지 복합적인 요소들에 따라 바뀌기 때문이다.
예를 들어 거의 정렬이 되어 있는 데이터의 경우에는 삽입 정렬과 셸 정렬이 빠르게 동작할 것이다. 하지만 데이터의 크기가 클 경우에는 셸 정렬보다 O(nlogn)의 시간 복잡도는 갖는 퀵 정렬, 병합 정렬, 힙 정렬이 더 좋을 것이다. 이렇게 데이터의 구성 및 크기에 따라 속도가 다르다는 것을 알 수 있다.
또한 셸 정렬과 퀵 정렬은 어느 것을 기준으로 삼는지에 따라, 즉 알고리즘의 구현 방식에 따라 속도가 달라질 것이다. 왜냐하면 셸 정렬의 경우 간격을 어떻게 설정했는지에 따라 성능이 달라지고 퀵 정렬 또한 pivot을 무엇으로 설정했는지에 따라 성능이 달라지기 때문이다. 이렇게 알고리즘을 어떻게 구현했는지에 따라 속도가 달라질 수 있다.
이외에도 여러가지의 복합적인 요소들 때문에 정렬의 속도가 달라진다. 그렇기 때문에 어떤 정렬 알고리즘이 가장 빠른지에 대해 확실하게 대답할 수 없으며, 주어진 상황에서 어떤 알고리즘을 사용해야 빠르게 정렬할 수 있을지 고려해야 한다.
👀 출처:
1. https://ko.wikipedia.org/wiki/%EC%85%B8_%EC%A0%95%EB%A0%AC
2. https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
'Computer Science > Algorithm' 카테고리의 다른 글
| 정렬 알고리즘 정리(1) - 버블 정렬, 선택 정렬, 삽입 정렬 (0) | 2023.02.13 |
|---|
